SQL에서의 Null 의 의미
- unknown: 알 수 없는 경우
- unavailable: 이용할 수 없는 경우
- not applicable: 해당 사항이 없음, 사용 불가
예를 들자면 birth_date 정보가 null 이면? 생일이 없을리는 없을테니, 생일 정보를 공개하지 않거나 아직 입력하지 않은 경우일 것이다. 그렇다면 birth_date가 null 인 A, B 가 있다면 둘은 생일이 같은 것인가? 당연히 알 수 없다. 같거나 다를 것이다. 그저 입력을 안했거나 생일을 공개하지 않았을 경우가 크다.
그럼 SQL 에서 null 을 비교연산자를 사용한다면? 정확한 결과가 도출되지 않을 것이다.
select id from employee where bitrh_date = NULL; (X)
select id from employee where bitrh_date is NULL; (O)즉 null 비교를 위해선 is 연산자(<-> is not)를 사용해줘야 정상적인 결과가 나오게 된다.
- SQL에서 Null 과 비교연산을 하게 되면 그 결과는 unknown 이 되며 이 의미는 true일수도, false 일수도 있다는 의미가 됨 -> 이를 three valued logic 이라 한다
| 예제 | 결과 |
| 1 = 1 | true |
| 1 != 1 | false |
| 1 = null | unknown |
| 1 != null | |
| 1 > null | |
| 1 <= null | |
| null = null |
위의 표를 보면 알다시피 비교 연산자에 null이 들어가면 어떤 식이든 unknown 이 됨을 알 수 있다.

위처럼 True and unknown 은 unknown 이 되며, false and unknown은 false 가 됨을 알 수 있다. 특이하게 unknown의 not은 unknown이 된다. 암기가 필요해보인다. false or unknown은 unknown 이 된다는 점도 암기하자. 사실 암기한다는 것 자체가 좀 그러한게, unknown 은 앞에서 말했다시피 true 가 될 수도 있고 false가 될 수도 있기 때문에 논리적으로 따져보면 암기할 것이 없다.
위의 결과가 중요한 이유는 지금까지 예시로 나왔던 where 절은 조건부의 결과가 true인 튜플만 리턴되므로 false 거나 unknown은 무시되기 때문이다. 예상하지 못한 결과를 판단할 때 필요하다.
Not in(or in) 사용 시 주의사항
v not in (v1, v2, v3)위의 의미를 풀어 사용하면, v != v1 and v != v2 and v != v3 이라는 것이다. 그런데 만약 v1, v2, v3 중 하나라도 null 이 있다면...? 위의 표에서 볼 수 있듯이 unknown 이 되어 원하는 결과를 얻을 수 없을 것이다.

여기까지 했다면 저번 서브쿼리 때 작성했던 in 과 관련된 쿼리문은 위험하다는 것을 확인할 수 있다. 하나의 값이라도 null 을 포함하고 있었다면 그 결과는 제대로 리턴되지 않았을 것이다.
select id, name
from department
where department.id not in (
select distinct employee.dept_id
from employee
where employee.birth_date >= '2000-01-01'
and employee.birth_date is not null
);in 의 경우는 employee.birth_date is not null 처럼 null 이 아니라는 검증을 추가해줘야 한다.
| 연산자 | in | not in | exists | not exists |
| 설명 | 입력된 값들 중 하나라도 일치하는 것이 있으면 조회 | 입력된 값들 중 하나라도 일치하지 않아야 조회 | 메인 쿼리에 접근하여 튜플을 가져오고 서브쿼리를 실행시켜 결과가 있는지 판단 | |
| 사용법 | 비교대상 값 직접 대입 가능 | 서브쿼리로만 사용 | ||
| 처리 | 내부적으로 or 연산자로 처리 | 내부적으로 and 연산자로 처리 | 서브쿼리 내 결과가 존재하는 경우(true) 메인쿼리 결과 조회 | 서브쿼리 내 결과가 존재하지 않는 경우(false) 메인쿼리결과 조회 |
| 주의사항 | null 값이 있으면 and 연산자의 특징상 옳은 정보마저도 unknown(false) 처리가 되므로 올바른 결과를 도출할 수 없게 됨 -> is not null 조건을 붙여서 조회를 생활화하기 |
서브쿼리가 true 면 해당하는 튜플이 조회되므로 동일한 값만 가져오려면 조건을 추가해줘야 함 | ||
JOIN
두 개 이상의 테이블들에 있는 데이터를 한번에 조회하는 것
select d.name from department d, employee e
where e.id = 1 and e.dept_id = d.id ;implicit Join
- from 절에는 테이블만 나열
- where 절에 join 조건을 명시
이 조건을 봤을 때 초기 select 방식에서 보았던 테이블 두개를 사용한 조회법은 암시적 조인이었음을 알 수 있다. 이런 경우 selection 조건과 join 조건이 where 절에 혼재되어 있어 가독성이 떨어지고, 복잡한 쿼리를 작성하다보면 누락될 가능성도 크다.
explicit join
select d.name
from employee e join department d on e.dept_id = d.id
where e.id = 1;- from 절에 join 키워드와 함께 테이블들을 명시
- on 절로 join 조건을 명시
위의 2가지 쿼리문은 결과적으로 같은 결과를 리턴한다. 다만 join 키워드를 사용하고 on 절에 조인 조건을 넣어줘서 가독성이 좋아졌다는 이점이 있다.
inner join
select * from employee e inner join department d on e.dept_id = d.id;두 테이블에서 join 조건을 만족(true)하는 튜플들이 결과로 조회되는 조인, 먼저 사용된 테이블 뒤로 join 다음에 기재된 테이블이 합쳐진 형태로 조인된다. 교집합의 형태로 이해하면 쉽다.
inner 가 생략되어도 기본적으로 join은 inner 조인이며, 조인 조건으로 비교 연산자를 사용할 수 있으나 null 의 경우는 결과로 조회되지 않기에 주의해야한다.
outer join
두 테이블에서 조인 조건을 만족하지 않는 튜플들도 결과 테이블에 포함하는 조인
- from table1 left outer join table2 on conditions
- from table1 right outer join table2 on conditions
- from table1 full outer join table2 on conditions: 합집합 --> MySQL 에선 지원하지 않고 PostgreSQL에선 지원함

left 의 의미는 왼쪽에 기재된 테이블을 기준으로 매칭되지 않는 null 값이 있더라도 전체 테이블을 조회해준다.
equi join
join 조건에 = 을 사용하는 조인을 의미
즉 위의 조인 예시들은 넓은 의미로 equi join 에 해당한다.

다만 equi 조인은 위처럼 한정지어 설명하는 시각도 존재한다고 한다.
using
만약 조인이 될 컬럼명이 같다면?
굳이 결과를 조회할 때 중복될 필요가 없을 것이다. 그런 경우엔 using 키워드를 사용하여 아래처럼 1컬럼으로 축약시켜서 조회해줄 수 있다. 그리고 using 을 사용해준 컬럼은 조회될 때 맨 앞의 컬럼으로 이동하게 된다.
select * from employee e inner join department d using(dept_id);- 두 테이블이 equi join 해줄 때 join 하고자 하는 atrribute명이 서로 같으면 using 으로 간단하게 작성이 가능
- 같은 이름의 컬럼명은 조회 테이블에서 1번만 표시
- equi join이 기준인 inner join, outer join 모두에서 사용이 가능
natural join
두 테이블에서 같은 이름을 가지는 모든 attribute 에 대해 equi join 을 실행하는 조인 방식, 같은 attribute명이어야 자동적으로 진행되는 것이므로 따로 join 조건을 명시하지 않기 때문에 문제가 생길 가능성이 크므로 지양
from table1 natural join table2
from table1 natural left join table2
from table1 natural right join table2
from table1 natural full join table2select *
from employee e natural inner join department d;
=
select *
from employee e inner join department d using(attribute명이 같은 것들);
cross join
두 테이블의 tuple 로 만들 수 있는 모든 조합인 카테시안 곱을 조회, 테이블을 합치기만 하므로 join 조건을 써주지 않는다. (on이나 using 을 사용해주면 inner join이 되어버린다)
-- implicit cross join
from table1, table2
-- explicit cross join
from table1 cross join table2위의 예시에서 보듯이 두 테이블을 from절에서 , 로 작성하거나 table명 사이에 cross join 을 써주면 cross join이 성립한다.
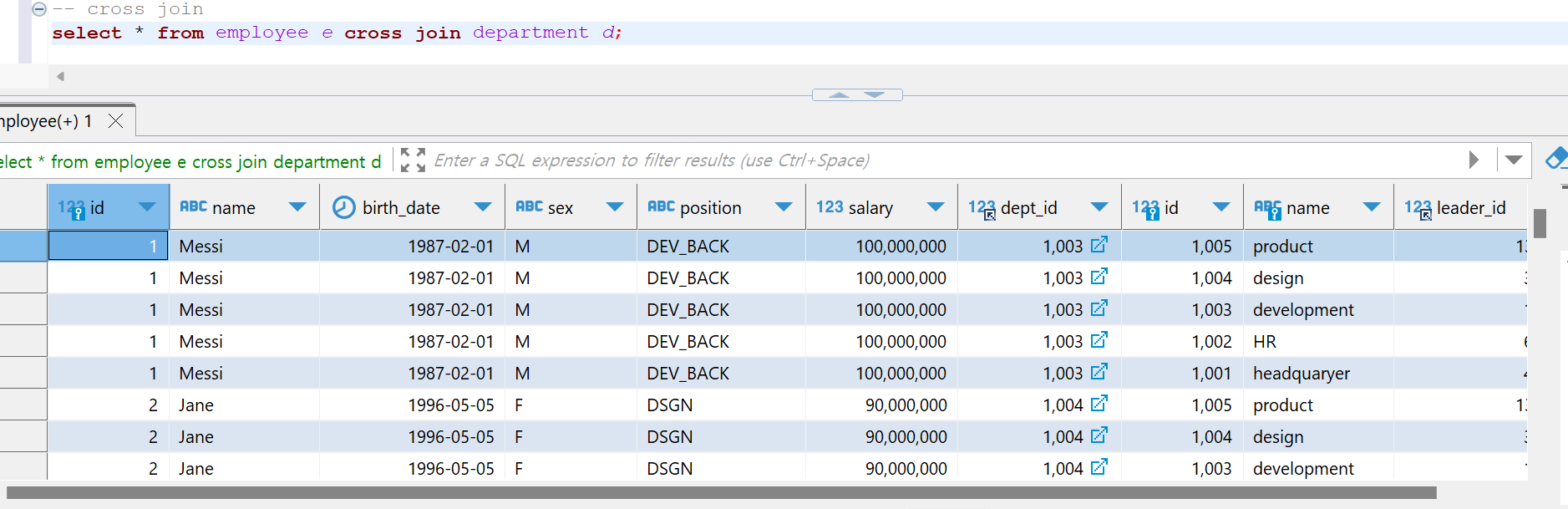
위처럼 모든 테이블의 정보의 조합이 조회된다.
- MySQL 에서의 cross join 주의사항
- 크로스 조인에 on/using 을 사용하면 inner join 으로 동작
- inner join 에서 on/using 절이 없으면 크로스 조인으로 동작
self join
1개의 테이블을 2개의 테이블처럼, 자기 자신의 테이블에 조인하는 것
위계(계층) 관계가 있는 컬럼들이 하나의 테이블에 있는 경우 셀프 조인을 사용
하나의 테이블을 두 번 나눠서 from 절에 써줘야 하므로 별칭을 지어줘야 한다.
select *
from table t1, table t2
where t1.fir_id = t2.sec_id;
select e.id, e.name, e.salary
from employee e left join department d on e.dept_id = d.id
where e.dept_id = 1003 and e.id not in (d.leader_id) ;위의 예시는 부서 1003 에서 리더를 제외한 직원들의 연봉정보를 조회하는 쿼리문이다. 결과적으로 보여야하는 정보를 기준으로 employee 를 써주었고, department 테이블을 조인시켜주되, employee 를 기준으로 조인해주었다.
select e.id, e.name, e.position, d.name
from employee e inner join works_on wo on e.id = wo.empl_id
left join department d on e.dept_id = d.id
where wo.proj_id = 2001;id가 2001인 프로젝트에 참여한 직원의 이름과 직군, 소속 부서명을 조회하려면 위처럼 employee, works_on, department 3개의 테이블이 조인되어야 한다. 차근히 직원의 이름과 직군, 어디에서 일했는가를 위해 employee와 works_on 테이블을 inner join 해준다. works_on 테이블은 애초에 project 와employee 테이블이 1:1대응하는 교차테이블이라 교집합으로 처리해도 된다. 그 다음 조인을 또 사용하고자 할 때 위처럼 그대로 뒤에 이어주면서 써주면 된다. 이미 inner join 된 가상의 테이블에 left join 을 해줌으로써 부서명을 참조해올 수 있게 되었다.
이렇게 SQL 에서 중요한 Join 이라는 산맥을 하나 넘었다. 이제 시작이다!
'Web Study > DataBase' 카테고리의 다른 글
| 데이터베이스 개론 & SQL - 8 (1) | 2024.02.13 |
|---|---|
| 데이터베이스 개론 & SQL - 7 (1) | 2024.02.11 |
| 데이터베이스 개론 & SQL - 4 (2) | 2024.02.04 |
| 데이터베이스 개론 & SQL - 3 (0) | 2024.02.03 |
| 데이터베이스 개론 & SQL - 2 (0) | 2024.02.01 |



