SQL (Structured Query Language)
현업에서 쓰이는 relational DBMS의 표준 언어이자 데이터베이스 언어의 종합(DDL+DML+VDL)
| relational data model | SQL |
| relation | table |
| attribute | column |
| tuple | row |
| domain | domain |
SQL에서 relation이란
multisets of tuple로, 중복된 tuple 을 허용한다.
SQL은 RDBMS의 표준 언어지만 실제 구현에 강제가 없으므로 RDBMS마다 제공하는 SQL 스펙이 조금씩 다름
시작 전, DBMS부터 다운 받기
1. MySQL
https://dev.mysql.com/downloads/mysql/
MySQL :: Download MySQL Community Server
Select Version: 8.3.0 Innovation 8.0.36 5.7.44 Select Operating System: Select Operating System… Microsoft Windows Ubuntu Linux Debian Linux SUSE Linux Enterprise Server Red Hat Enterprise Linux / Oracle Linux Fedora Linux - Generic Oracle Solaris macOS
dev.mysql.com
2. PostgreSQL
https://www.enterprisedb.com/downloads/postgres-postgresql-downloads
Community DL Page
Note: EDB no longer provides Linux installers for PostgreSQL 11 and later versions, and users are encouraged to use the platform-native packages. Version 10.x and below will be supported until their end of life. For more information, please see this blog p
www.enterprisedb.com
강의에선 MySQL을 사용한다고 한다. 나는 Postgre를 사용해야해서 공부할 땐 MySQL을, 실습으로 Postgre를 병행할 예정이다. 이 두 프로그램을 깔아주고 매번 DBMS 프로그램을 왔다갔다 하기 귀찮고 번거로우므로 통합 DBMS인 DBeaver 도 다운 받아준다.
3. DBeaver
Download | DBeaver Community
Download DBeaver Community 23.3.3 Released on january 22th 2024 (Milestones). It is free and open source (license). Also you can get it from the GitHub mirror. DBeaver PRO 23.3 Released on December 11th, 2023 PRO version website: dbeaver.com Trial version
dbeaver.io
이 녀석은 여러 DBMS를 통합해둔 프로그램이라고 보면 된다. 기본적으로 사용하려는 DBMS가 깔려있어야 되며, DBMS로 Database를 미리 만들어두는 것을 추천한다.
추가로 DBMS를 터미널에서 작성하고자 한다면, 기본으로 환경변수 Path가 설정되어 있지 않을 가능성이 크다. 나같은 경우에도 그러하였다.
시스템 속성의 환경변수에서 PATH 부분을 ; 을 구분자로 하여 MySQL과 PostgreSQL의 bin 폴더 경로를 넣어준다. 이렇게 하지 않으면 cmd 측에서 mysql, psql 로 접근이 불가하고 매번 전용 커맨드라인 프로그램을 틀어줘야 한다. 설치시 다른걸 건드리지 않았다는 전제하에 보통 주소는 C:\Program Files 폴더 아래에 위치할 것이다.
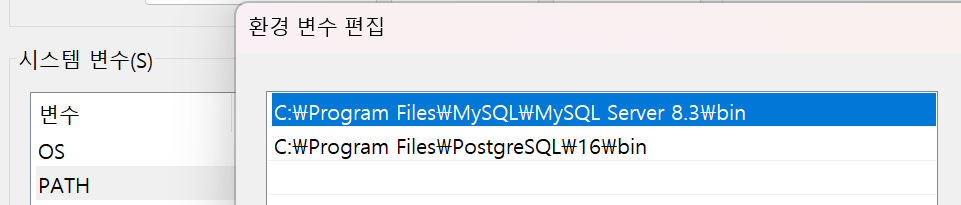
DBMS 접속하기
커맨드라인 전용 앱이 아닌 이상 cmd 창에서 아래와 같이 입력하면 cmd창에서 해당 DBMS와 접속이 가능하다. 비밀번호는 설치할 때 정한 그 내용이니까 절대 잊지 말자... 이거 까먹으면 재설정하기 무지 귀찮다.
mysql -u root -p
psql -U postgres
접속해주면 쉘 부분이 각 DBMS로 변하는 것을 볼 수 있다.
그럼 우선 간단하게 강의를 따라할 겸 사용할 DB를 만들어준다.
create database <MYSQL DB명> characterset utf8;
create database <PostgreSQL DB명>;
// 참고로 drop database <DB명>; 으로 데이터베이스를 삭제할 수 있다.
이제 DBeaver 에서 해당 DB를 연결해주면 기본 설정이 끝난다..

정상적인 접속이 성공하면 초록 화살표가 보일 것이다. 이제부터 DBeaver 로 DB를 관리해줄 수 있게 되었다.
추가로 MySQL에서 현재 선택된 데이터베이스를 확인하려면 아래의 select 명령어를 사용해준다. 데이터베이스를 지정하지 않았다면 Null 이 뜰것이다.
select database();use 명령어를 사용하여 데이터베이스를 사용함을 명시해준다.
use <DB명>;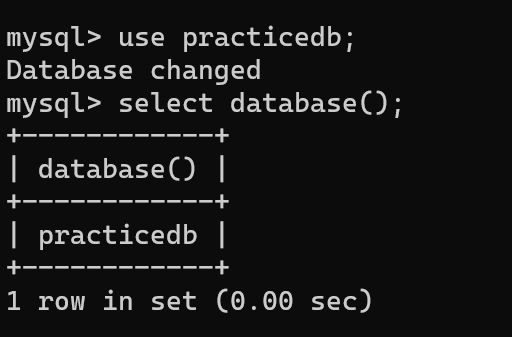
MySQL의 Database와 Schema는 같은 의미이다.
하지만 PostgreSQL 등에선 Schema가 Database의 namespace를 의미하므로 다른 의미이다. 즉, PostgreSQL 에서는 하나의 Database 에 여러 개의 Schema를 가질 수 있지만 MySQL은 Database 와 Schema가 1:1 관계이다.
RDB 만들기
부서, 사원, 프로젝트 관련 정보들을 저장할 수 있는 관계형 데이터베이스 만들기를 같이 하게된다. (MySQL)
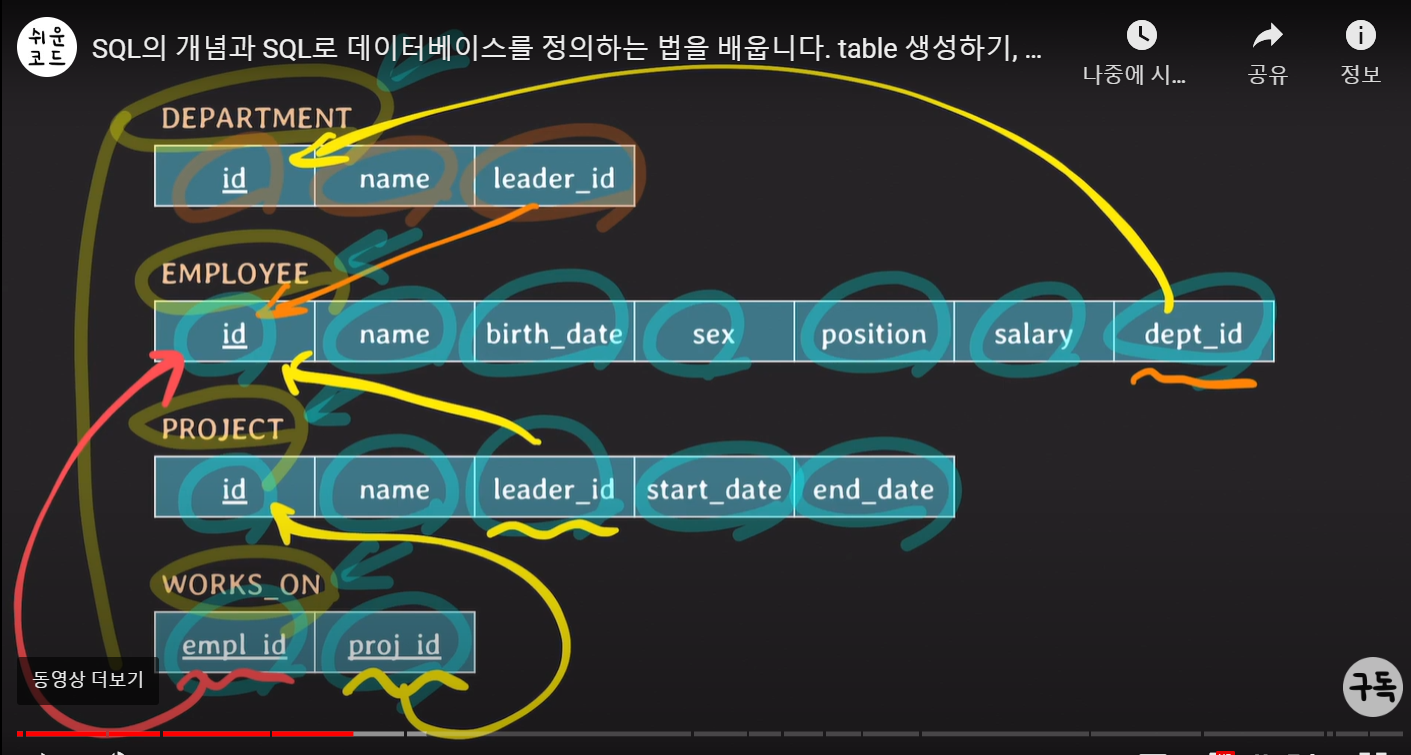
relation과 attribute는 위와 같고 화살표가 relationship에 해당한다.
테이블 생성
create table <Table명>() 형태로 만들 수 있으며 각 컬럼에 해당 하는 정보를 , 구분자로 작성해준다. 컬럼명 타입 제약사항 순이다.
create table DEPARTMENT(
id int primary key,
name varchar(20) not null unique,
leader_id int
);
위의 타입은 직관적이긴 하지만 추가로 알아둘 것도 있으니 정리해본다.
숫자 타입
| 종류 | 크기 | MySQL | PostgreSQL | |
| 정수 | 정수 저장 | 1 byte | TINYINT | X |
| 2 byte | SMALLINT | |||
| 3byte | MEDIUMINT | X | ||
| 4byte | INT OR INTEGER | |||
| 8byte | BICINT | |||
| 부동 소수점 | 실수를 저장할 때 사용하나 고정 소수점 방식에 비해 정확하지 않음 | 4byte | FLOAT | |
| 8byte | DOUBLE OR DOUCLE PRECISION | |||
| 고정 소수점 | 실수를 정확하게 저장할 때사용 | variable | DECIMAL OR NUMERIC | |
문자열 타입
| 종류 | MySQL | PostgreSQL | |
| 고정 크기 문자열 | 최대 몇 개의 문자를 가지는 문자열을저장할 지 지정 저장될 문자열의 길이가 최대 길이보다 작으면 나머지를 공백으로 채워서 저장 |
CHAR(N) 0 <= N <= 255 |
CHAR(N) |
| 가변 크기 문자열 | 최대 몇 개의 문자를 가지는 문자열을 저장할지 지정 저장된 문자열의 길이만큼만 저장 |
VARCHAR(N) 0 <= N <= 65,535 |
VARCAHR(N) |
| 사이즈가 큰 문자열 | 사이즈가 큰 문자열 저장 | TINYTEXT (VARCHAR와 거의 유사함) TEXT MEDIUMTEXT LONGTEXT |
TEXT |
문자열의 경우, PostgreSQL은 문자열의 길이에 무관하게 varchar 를 사용하는 것이 성능상 이점이 있다고 하며 MySQL의 경우 varchar를 사용하면 메모리상 이점은 있겠지만 성능상 문제가 생길수 있으므로 문자열의 크기가 고정인 경우 char 를 사용하는 것이 성능상 이점이 있다고 한다.
날짜/시간 타입
| 종류 | MySQL | |
| 날짜 | 년,월,일 저장 YYYY-MM-DD |
DATE |
| 시간 | 시,분,초 저장 hh:mm:ss |
TIME |
| 날짜와 시간 | 날짜와 시간을 함께 YYYY-MM-DD hh:mm:ss |
DATETIME 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| TIMESTAMP + 서버의 위치에 따른 time-zone 반영 (UTC) 1970-01-01 00:00:01 UTC ~ 2038-01-19 03:14:07 UTC |
그밖에 타입
| 종류 | MySQL | |
| byte-string | 문자열이 아닌 byte string 저장 | BINARY VARBINARY BLOB |
| boolean | true/false | X |
| 위치 | 위치 관련 정보 | GEOMETRY |
| JSON | json 형태 데이터 저장 | JSON |
create table EMPLOYEE(
id INT primary key,
name varchar(30) not null,
birth_date date,
sex char(1) check(sex in ('M', 'F')),
position varchar(10),
salary int default 50000000,
dept_id int,
foreign key(dept_id) references DEPARTMENT(id)
on delete set null on update cascade,
check (salary >= 50000000)
);
select * from employee;Primary key
tuple을 식별하기 위해 사용하는 하나 이상의 attribute로 구성
중복된 값을 가질 수 없으며 Null 도 가질 수 없게끔 제약한다.
-- attribute 하나일 때
create table 테이블명(
id int primary key,
);
-- attribute 가 하나 이상 일 때
create table 테이블명(
...
primary key(team_id, back_num)
);
Unique
attribute에 중복된 값을 가질 수 없게 제약한다. 다만 Null 은 DBMS에 따라 다르지만 중복을 허용할수도 있다.
-- attribute 하나
create table 테이블명(
id int unique,
);
-- attribute 하나 이상
create table 테이블명(
...
unique(team_id, back_num)
);
Not Null
Null 을 가질 수 없는 제약사항
-- attribute 하나
create table 테이블명(
id int not null,
);
Default
attribute의기본값을 정의할 때 사용
새로운 tuple 을 저장할 때 해당 속성의 값이 없다면 기본값으로 저장된다.
Check
attribute 값을 제한하고 싶을 때 사용
-- attribute 하나
create table 테이블명(
age int check(age >= 19),
);
-- attribute 하나 이상
create table 테이블명(
...
check(start_date < end_date)
);
Foreign key
attribute 가 다른 table의 primary key나 unique key를 참조할 때 사용 (pk를 참조하면 식별 관계, uk를 참조하면 비식별 관계)
create table 테이블명(
...
속성명 타입,
foreign key(속성명, ...)
references 참조한 테이블명(참조한 속성명)
on delete reference_option -- 삭제 됐을 때 제약사항
on update reference_option -- 업데이트 됐을 때 제약사항
);
-- ex
create table 테이블명(
...
dept_id int,
foreign key(dept_id)
references DEPARTMENT(id)
on delete set null
on update cascade
);
-- 외래키 부분의 구문을 풀이해보다면, dept_id 속성은 DEPARTMENT 테이블의 id를 참조한 속성이며,
-- 원래 테이블인 DEPARTMENT의 id의 value가 삭제될 때 null 값으로,
-- 업데이트 될 때는 같이 업데이트하여 수정하라는 의미가 된다.| reference_option | MySQL | PostgreSQL | |
| cascade | 참조값의 삭제/변경을 그대로 반영 | O | O |
| set null | 참조값이 삭제/변경 시 null 로 변경 | ||
| restrict | 참조값이 삭제/변경 되는 것을 금지 | ||
| no action | restrict 와 유사하나 참조되는 테이블에서 데이터를 삭제하거나 수정해도 참조하는 테이블의 데이터는 삭제/변경 되지 않는 것 | X | |
| set default | 참조값이 삭제/변경 시 기본값으로 변경 | X | |
Constraint 이름 명시
제약 사항을 명명하여 무엇을 위반했는지 파악을 쉽게 만들 수 있다. 이름을 지어주지 않으면 에러 메세지에 정확한 컬럼명이 뜨지 않아 디버깅 시간이 늘어날 수 있다.
create table TEST(
age int Constraint age_over_20 check(age > 20)
);컬럼명 타입 constraint 제약사항명 check(조건) 으로 이름 지어 줄 수 있다.
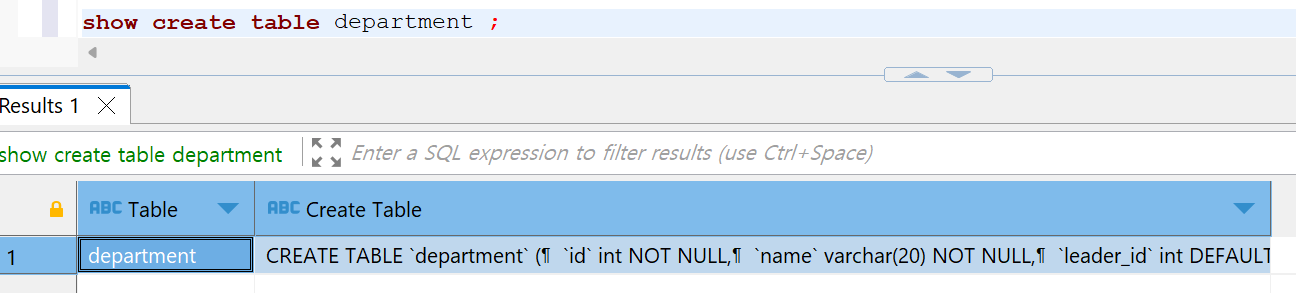
테이블 수정하기
alter table 테이블명 <변경해줄 내용>
alter table department add foreign key(leader_id)
references employee(id)
on delete set null on update cascade;
이미 서비스 중인 테이블의 스키마를 변경하는 것은 변경 작업 전 백엔드 영향이 없을지 검토한 다음에 변경하는 것이 중요하다.
테이블 삭제
drop table <테이블명>;
'Web Study > DataBase' 카테고리의 다른 글
| 데이터베이스 개론 & SQL - 4 (2) | 2024.02.04 |
|---|---|
| 데이터베이스 개론 & SQL - 3 (0) | 2024.02.03 |
| 데이터베이스 개론 & SQL - 1 (0) | 2024.01.31 |
| SQLD 합격! 그리고 DAsP 도전 (0) | 2023.12.21 |
| SQL - 실체 엔터티에 대해... (0) | 2023.12.11 |


