Stored function
계산 용도의 목적으로 RDBMS 내부에 function 형태로 저장해서 쓸 수 있는 쿼리문
- 사용자가 정의한 함수
- DBMS에 저장되고 사용되는 함수
- Select, delete, update, insert 문에서 사용될 수 있다
delimiter
delimiter $$
&&구문문자를 의미하는 delimiter 는 프로그래밍 언어에서 ;을 의미하는 문법의 끝을 나타내는 역할을 하는 키워드를 지칭할 때 사용한다. 사용자 정의 함수를 만들어주기 전 보통 사용되는 ;을 $$ 으로 바꿔줌으로써 함수 안에 써줄 ;과 서로 혼동되지 않게 해주는 용도라고 생각하면 된다.
위처럼 delimiter 로 사용할 문자를 적어주고, 마지막에 문법이 끝나면 지정해준 문자로 끝 마무리를 지어준다.
create function
create function 함수명(매개변수)
returns 리턴 타입
Begin
함수내용;
return 리턴내용;
End함수는 위처럼 정의해준다. 함수의 내용은 Begin 과 End 사이에 작성해준다.
delimiter $$
create function id_generator()
returns int
no sql
begin
return (1000000000 + floor(rand()*1000000000));
end
$$
delimiter;위의 예시는 직원의 ID를 열자리 정수로 랜덤하게 발급하기 위한 함수이다. 맨 앞자리가 1로 고정이므로 1000000000 을 더해준 것이다. 여기서 No SQL 구문의 의미는 옵션 중 하나로, 데이터 사용 특성에 관한 정보를 알려주는 옵션이다.
- MySQL의 정보성 옵션
- Contains SQL: 데이터를 읽거나 쓰는 명령문이 포함되지 않음, 기본값
- No SQL: SQL문이 존재하지 않음
- Reads SQL Data: 데이터를 읽는 명령문이 포함되어 있지만 쓰는 명령문은 없음
- Modifies SQL Data: 데이터를 쓸 수 있는 명령문이 있음
이렇게 총 4가지의 옵션을 가지며 이 정보를 잘못 쓰나, 아니나에 무관하게 영향을 주진 않는다. 다만 mysql의 스키마 routines 라는 시스템 테이블에 저장된다. 이를 통해 SQL_DATA_ACCESS 컬럼에 저장되어 관리해줄 수 있다고 한다.

위의 함수를 사용하고자 할 땐?
insert into employee values (id_generator(), 'GGU', '1991-03-11', 'F', 'PO', 100000000, 1005);이렇게 DML 안에 사용해줄 수 있다.
* 다만 DBeaver 에서 create function 이 정상적으로 작동하지 않고 있다! 계속해도 왜 안되나 싶었더니 개발 이슈였었다. (24년 2월 5일까진 안되는 것 확인) https://github.com/dbeaver/dbeaver/issues/17994
SQL error [1305] [42000] · Issue #17994 · dbeaver/dbeaver
Description I can't save and use it when I connect to mysql and create procedure and function ( show SQL error [1305] [42000]). It works fine when I use other tools and Command line client. DBeaver...
github.com
그래서 어쩔 수 없이 sql cmd 창을 활용하여 작성하였다.
만들어준 함수를 확인하려면 테이블처럼 아래의 명령어로 확인해줄 수 있다.
show create function 함수명;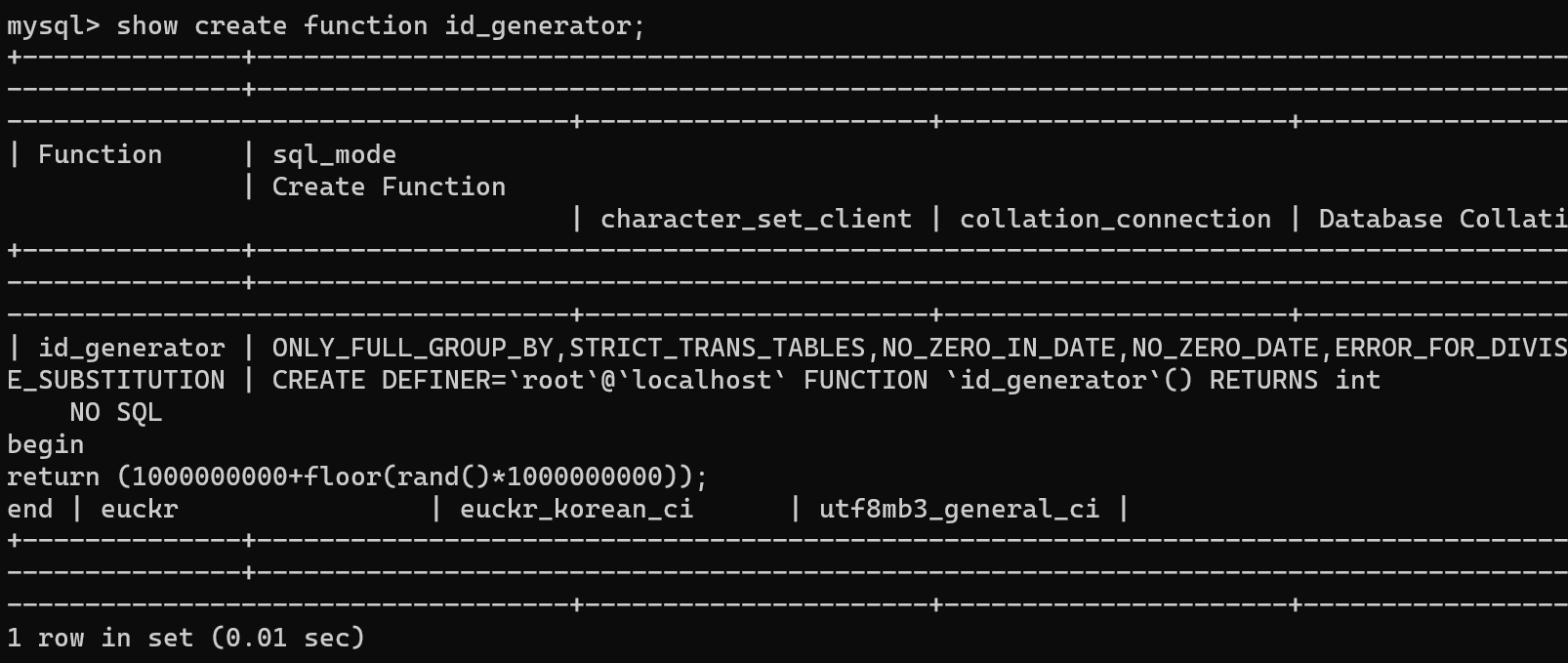
show function status where DB = 'DB명';
-- ex
show function status where DB = 'testdb';해당 명령어로 DB에 해당하는 모든 함수를 확인해줄 수 있다.
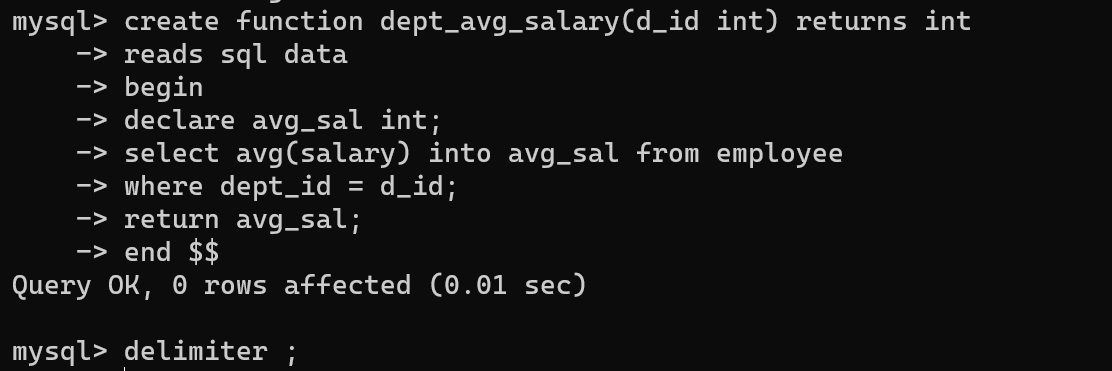
그렇다면 해당 쿼리문은 무슨 함수일까? 부서번호를 매개변수로 받아 해당 부서의 평균연봉을 리턴해주는 함수이다.
declare 변수명 타입;중간에 보면 전의 예시에선 보지 못한 declare 키워드가 보일 것이다. 해당 키워드는 변수를 선언할 때 사용하는 키워드로, 위의 함수에선 부서의 평균연봉값 조회한 것을 넣어줘서 반환해주는 것을 알 수 있다.
위에서 만들어준 변수는 into 키워드를 사용하여 조회된 값을 넣어줄 수 있다.
추가로, declare 키워드 대신 @를 사용하여 변수 선언을 해줄 수 있는 방법도 있는데,
delimiter $$
create function dept_avg_salary(d_id int)
returns int
reads sql data
begin
select avg(salary) into @avg_sal
from employee where dept_id = d_id;
return @avg_sal;
end $$
delimiter ;위처럼 declare 절의 삭제하고 변수로 사용해줄 값 앞에 @ 를 붙이는 것이다.
select *, dept_avg_salary(id) from department;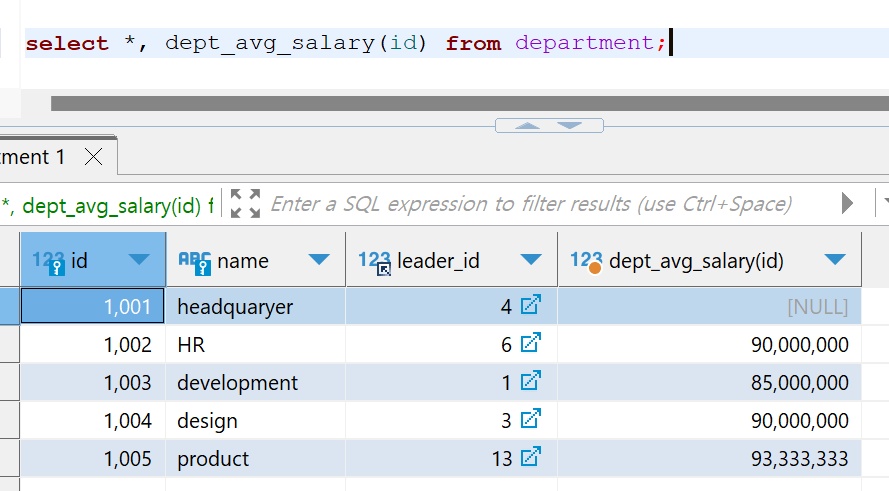
전에는 조인이나 서브쿼리, 그룹핑을 통하여 보여줄 수 있었던 결과를 함수를 만듦으로써 간편하게 실행함을 알 수 있다.
delimiter $$
create function toeic_pass_fail(toeic_score int)
returns char(4)
no sql
begin
declare pass_fail char(4);
if toeic_score is null then set pass_fail = 'fail';
elseif toeic_score < 800 then set pass_fail = 'fail';
else set pass_fail = 'pass';
end if;
return pass_fail;
end $$
delimiter ;토익 점수를 토대로 합불합에 대한 함수를 만들면 위와 같다. 함수 자체는 어렵지 않지만 create function 으로 만들어보는 건 아직 헷갈린다. 안쪽의 문법적인 요소를 확인해보자면 if - elseif - else 문을 사용하고 있음을 알 수 있다.
그리고 변수에 전의 예제에선 into 를 사용해줬으나 이번엔 set으로 변수값을 넣어주고 있다.
이렇듯 stored function 은 같은 작업을 반복해서 실행하거나, case 키워드를 사용하여 분기 처리, 에러 핸들링이나 일부러 에러 상황을 만들어보는 등의 다양한 동작을 정의하며 사용할 수 있다.
함수를 만드는 것은 어려웠지만 삭제하는 것은 쉽다.
drop function 함수명;
Tree tier architecture?
클라이언트-서버 모델로 개발 작업을 하게 된다. 이 모델은 아래와 같이 3개의 티어로 나뉘게 된다.
- Presentation tier
- 사용자에게 보여지는 부분 담당
- HTML, CSS, JS ...
- Logic tier (application tier)
- 서비스와 관련된 기능과 정책 등 비즈니스 로직 담당
- Java+spring, Python+jdango, ...
- Data tier
- 데이터를 저장하고 관리하고 제공하는 부분 담당
- MySQL, PostgreSQL, ...
stored function 의 사용 시기?
1. util 함수로 쓸 때
2. 비즈니스 로직의 경우는 지양
즉 Logic tier 와 Data tier 에 비즈니스 로직이 분산되면 그만큼 유지보수 비용이 증가 하게 될 것이다. 그러므로 stored function 으로는 비즈니스 로직을 계산하는 등의 함수는 지양하는 것이 좋다고 한다.
그럼 위에서 만들었던 함수들의 예시를 가지고 사용 여부에 대한 유효검사를 해보면,
- dept_avg_salary : 비즈니스 로직이 없으므로 stored function 에 적합
- id_generator : 비즈니스 로직이 약간 있음
- toeic_pass_fail : 비즈니스 로직이 있으므로 stored function 에 부적합
이러한 예시는 회사나 프로젝트, 상황에 따라 달라질 수 있는 부분이라 계속해서 논의가 필요하다고 한다.
'Web Study > DataBase' 카테고리의 다른 글
| 데이터베이스 개론 & SQL - 마지막 (1) | 2024.02.14 |
|---|---|
| 데이터베이스 개론 & SQL - 8 (1) | 2024.02.13 |
| 데이터베이스 개론 & SQL - 5 (1) | 2024.02.05 |
| 데이터베이스 개론 & SQL - 4 (2) | 2024.02.04 |
| 데이터베이스 개론 & SQL - 3 (0) | 2024.02.03 |



