SQLAlchemy
RDBMS ORM(Object Relational Mapping) 으로, DBMS의 데이터베이스 구조를 파이썬의 클래스(객체)화 시키는 라이브러리이다. 객체 지향적인 코드, 즉 SQL문 대신 클래스처럼 사용할 수 있게 도와준다. 특히 DBMS 종속성이 줄어든다는 장점이 존재한다.
다만 ORM만으로 서비스 구현이 어렵다는 점과 프로시저가 많으면 장점이 무색해진다는 단점도 있다.
SQLAlchemy
The Database Toolkit for Python
www.sqlalchemy.org
ORM (Object Relational Mapping)
직관적으로 해석하자면 객체 관계 맵핑을 의미한다. 즉 객체와 관계형 데이터베이스를 자동으로 연결하는 것이다. 객체 지향 프로그래밍은 클래스를 사용하고 관계형 데이터베이스는 테이블을 사용하여 모델 간 괴리가 존재하는데 ORM을 통하여 객체 간의 관계를 바탕으로 SQL 작성을 돕는다.
| 장점 | 단점 |
| 객체 지향적 코드를 사용하여 직관적, 비즈니스 로직에 집중 가능 | 설계상 신중하게 하지 않을 경우 난이도가 올라가고 일관성이 무너질 수 있음 |
| 재사용 및 유지보수 용이 | 속도 저하 위험 -> 별도의 튜닝이 필요한 경우는 사용이 힘듦 |
| DBMS 종속성 감소 | 프로시저는 객체로 바꿔줘야하는 번거로움으로 생산성이 하락할 수 있 |
SQLAlchemy 모듈
from sqlalchemy import create_engine, Table, Columncreate_engine 은 각 DBMS 마다 설정해주는 중간 다리 역할을 한다. 그래서 여러 DBMS를 연동시키고자 한다면 해당 함수를 사용해준다.
engine = create_engine(' ,,, ')
from sqlalchemy import Integer, String, Boolean, Date, Time, Float, BigInt, Binary, LargeBinary, Blob, Clob, DateTime, TIMESTAMP위에서 언급한대로 데이터베이스와 클래스 간 연동을 해주려면 그에 맞는 타입으로 변환시켜줘야 할 것이다. SQLAlchemy의 타입들을 활용해주면 별다른 처리없이 데이터베이스 구조를 클래스화할 수 있게 된다.
from sqlalchemy.orm import scoped_session, sessionmakerscoped_session 은 전역적으로 세션을 만들어준다.
from sqlalchemy.ext.delarative from declarative_base
from sqlalchemy.exc from SQLAlchemyException
SQLAlchemy와 DBMS 연결하기
mysql_url = 'mysql+pymysql://USER:PASSWORD@IP/DBNAME?charset=utf8"
engine = create_engine(mysql_url, echo=True)위에서 말했듯이 create_engine() 함수로 연결해준다. echo 파라미터는 True일 때 아래와 같이 실행된 SQLAlchemy가 변환된 SQL문을 확인할 수 있다.

db_sesion = scoped_session(sessionmaker(autocommit=False, autoflush=False, bind=engine))scoped_session과 sessionmaker 로 전역적으로 사용 가능한 세션을 만들어준다. scoped_session 은 동일 쓰레드 간 세션의 충돌을 방지하기 위해 사용된다고 한다.
sessionmaker 의 bind 파라미터는 DBMS 엔진을 연결시켜주고 알다시피 기본 MySQL은 Auto commit 기능이 꺼져 있으므로 위와 같이 파라미터를 지정해준다. Auto Flush 파라미터는 flush 기능이 트랜잭션을 데이터베이스로 전송만 해준 커밋이 되지 않은 상태이다.
팩토리 패턴과 sessionmaker
인스턴스를 만드는 절차를 추상화하는 패턴인 생성 패턴의 일부이다. 이는 시스템이 어떤 클래스를 사용하는지, 어떻게 만들어지고 결합하는지와 무관하게 처리가 가능하다.
그중에서도 팩토리 패턴은 객체를 생성하는인터페이스를 미리 정의하고 인스턴스를 만들 클래스의 결정을 서브 클래스에서 정하는 패턴이다. 당장 자신이 생성해야하는 객체의 클래스를 예측할 수 없고, 인스턴스를 만드는 시점을 서브 클래스로 미루는 패턴이다. 이는 각 DBMS마다 세션을 만드는 법이 매우 상이하기 때문에 sessionmaker 를 팩토리 패턴으로 만든 것이다.
여기까지 엔진과 세션을 만들어 준 것이다.
Base = declarative_base()
Base.query = db_session.query_property()declarative_base() 함수는 데이터베이스의 테이블과 클래스를 매핑하기 위한 base 클래스를 생성해주게 된다. base 클래스는 해당 클래스를 상속 받는 자식 클래스들 모두 테이블과 맵핑되는 클래스로 인식하게 된다.
def init_database():
Base.metadata.create_all(bind=engine)
SQLAlchemy/DBMS 연결 관리
데코레이션 중 @app.before_first_request 라는 것을 저번 게시글에서 정리한 적이 있었다. 해당 이벤트 핸들러는 최초의 실행 단 1번만 실행되므로 위에서 작성해준 DB 초기화 함수를 실행시켜주기 안성 맞춤으로 보인다.
반대로 @app.teardown_appcontext 데코레이션은 요청의 response 까지 끝난 상태에 수행되므로 이를 사용하여 세션 연결을 끊어주는데 사용한다.
@app.before_first_request
def beforeFirstRequest():
print ('시작!')
init_database()
@app.teardown_appcontext #response가 끝났을 때 실행
def teardownAppcontext(exception):
print('끝!', exception)
db_session.remove()
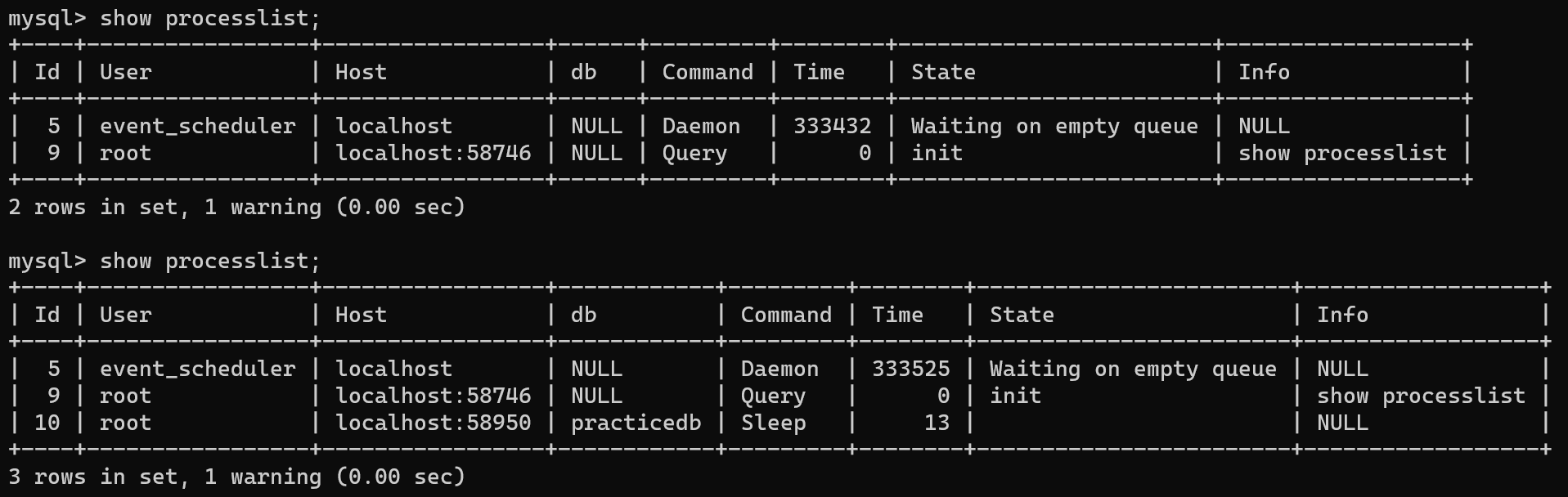
세션을 일부러 끊어주지 않는한, show processlist 의 결과로 나온 10번 Id 가 플라스크 서버에서 사용되고 있음을 알 수 있다. 이러한 이유로 세션을 끊어주는 과정을 추가해야 한다.
테이블/클래스 맵핑
맵핑을 위해 임의로 User 테이블을 만들어준다.
Data Model (DTO)
데이터베이스 테이블에서 읽어온 정보들이 클래스화 되어 메모리상에 Object pooling 이 되어 재차 select 할 필요가 없어진다.
위에서 설명했듯이 Base 클래스를 상속 받아서 아래 구현해준다. 이때 __tablename__에는 맵핑해줄 테이블명을 적고, Column에는 테이블의 타입 및 제약사항을 맞춰 적어줘야 한다.
class User(Base):
__tablename__ = 'user'
id = Column(Integer, primary_key=True)
email = Column(String, unique=True)
nickname = Column(String)
def __init__(self, email=None, nickname='손님'):
self.email = email
self.nickname = nickname
def __repr__(self):
return 'User %r %r' %(self.email, self.nickname)그리고 이렇게 만들어준 클래스를 임의로 아래처럼 가져오고 인스턴스를 만들어준 다음, db session에 add로 올린 다음, commit() 을 해줘서 추가 사항을 저장해준다.
__repr__
어떤 객체의 외부에 노출되는 표현을 나타내준다. 즉 해당 클래스에 정의된 무언가를 출력 가능한 문자열 형태로 반환해주게 되는 함수이다.
알다시피 __str__ 함수또한 객체의 문자열을 반환한다. 그럼 __ repr __ 와 __ str __ 은 무엇이 다를까? 가장 큰 차이점은 둘의 사용 용도가 매우 다르다는 점이다. __ str __ 의 대표적 예시가 print() 함수로 타입이 다른 값들을 넣어주어도 문자열 형태로 출력하는 것을 알 수 있다. 이처럼 추가적 가공이나 호환될 수 있도록 문자열화 해주는 곳에 __ str __ 이 쓰인다. 반면 __ repr __ 는 사람이 이해할 수 있게 객체를 표현하는 것에 주력한다는 점에 초점을 맞추고 있다.
Insert
@app.route('/')
def home():
u = User('xxx@gmail.com', 'Hong')
db_session.add(u)
db_session.commit()
return "home"정상적으로 입력해준 값이 DB에 저장됐음을 알 수 있다.
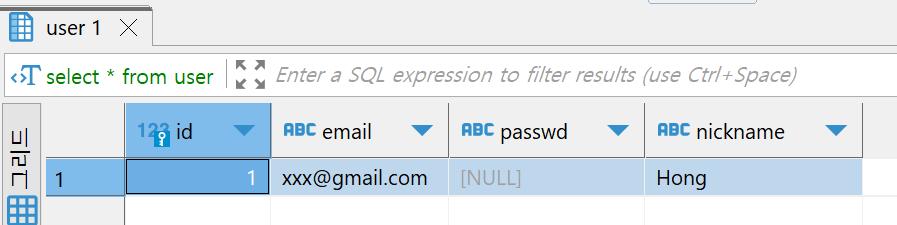
Select
그럼 User 테이블을 위처럼 DBMS에서 읽어오는 것이 아니라, python으로 읽어오고자 한다면,
@app.route('/user')
def user():
try:
users = db_session.query(User).all()
return "결과: " + str(users)
except SQLAlchemyError as sqlerr:
print('SQLAlchemy: ', sqlerr)
except:
print('Error')이렇게 db 세션을 사용하여 query 를 실행시켜도 되고, 아래처럼 클래스 내 query 속성으로 사용해줘도 상관 없이 동일한 결과가 나오게 된다.
users = User.query.all()
Update
users = User.query.filter(User.id == 3).first()
users.email = 'GGG@gmial.com'
db_session.add(users)
db_session.commit()Update 해주기 위해서 우선 변경시켜줄 레코드를 찾은 다음, 딕셔너리 값을 변경해주는 것과 같이 값을 수정해준다. 이 상태에서 DBMS를 확인해봐도 값이 변하지 않았음을 알 수 있다. 이 값을 DB상에 올려주려면 당연히 db session에 add 로 변경된 내용을 추가하고, commit 까지 해줘야 변경 사항이 반영된다.
Delete
삭제도 Update 와 동일하게 우선 삭제해줄 정보를 찾은 다음 db session의 delete() 메서드를 사용하여 삭제처리 해준다.
user = User.query.filter(User.id == 7).first()
db_session.delete(user)
db_session.commit()
Rollback
db_session.rollback()
쿼리문을 직접 작성하기
s = db_session()
change = s.execute(update(User).where(User.id == 4).values(nickname = "Pika"))
db_session.add(change)
db_session.commit()
s.close()db_session을 가져와서 인스턴스화 해주면 서브 세션이 생기게 된다. 위의 과정과 다르게 직접 서브 세션측에 execute 메서드를 통해 쿼리문을 실행시켜줄 수 있다. 이때 쿼리가 끝나면 서브쿼리를 꼭 close 해줘야 한다.
쿼리문에 사용되는 함수들은 아래와 같이 별도로 import 해주고 작성해준다.
from sqlalchemy import select, update
result = s.execute(select(User).where(User.id > 2))
Record = namedtuple('User', result.keys())
records = [Record(*r) for r in result.fetchall()]
for record in records:
print(record, type(record))위의 예시는 select 하는 구문으로 id가 2이상인 유저들을 모두 가져오게 된다. result 로 인해 읽어온 테이블의 keys 는 컬럼에 해당한다. 그리고 Record 네임드튜플은 result의 fetchall() 메서드는 쿼리문을 읽어온 결과값들이 for 문을 돌면서 각각의 원소(r)에 접근하여 *r로, 튜플형태가 벗겨져서 네임드튜플에 들어가게 되는 것이다.
namedtuple
from collections import namedtuple
튜플은 순서가 있지만 값을 변경할 수 없어데이터 값 수정이 필요없을 때 사용하게 된다. 인덱스에 따라 값을 판단해야하는 불편함이 있는 튜플과 달리 네임드튜플은 인덱스와 키이름으로 접근이 가능한 자료형이다. 다만 기본 자료형이 아니라 위처럼 import 해줘야 한다. 일반 객체 형태보다 메모리를 적게 사용하니 적절히 사용해주자. (메모리 효율성: 리스트 < 튜플 < 네임드튜플)
*
기존의 곱셈이나 거듭제곱의 연산말고 *은 unpacking 에도 사용된다. 언패킹이란 괄호 안에 담긴 데이터들을 풀어주는 것이다. (자바스크립트의 ...과 동일하다고 생각하면 될거 같다) 딕셔너리의 경우 *을 붙여주면 키값으로 풀리게 된다.
그외에 *args, **kwargs 를 파라미터 부분에서 본 적이 있을 것이다. 이는 가변 인자를 표현하는 키워드로 인자의 개수를 모를 때 사용해준다.
- *args : 위치에 따라 지정해주는 인자
- *kwargs : 키워드를 갖는 인자
def tmp1(*args):
print(args, type(args))
def tmp2(**kwargs):
print(kwargs, type(kwargs))
tmp1("key1", "key2", "key3") # ("key1", "key2", "key3") <class 'tuple'>
tmp2(key1="1", key2="2", key3="3") # {"key1"="1", "key2"="2", "key3"="3"} <class 'dict'>이처럼 args 는 튜플 형태로, kwargs 는 키와 값으로 이루어진 딕셔너리 형태로 들어오게 된다.
'Python > Flask' 카테고리의 다른 글
| Flask + PostgreSQL + React - 1 (0) | 2024.03.05 |
|---|---|
| Jinja2 and Werkzeug? (0) | 2024.03.04 |
| flask 웹개발 기초 정리 - 3 (feat. SQLAlchemy) (1) | 2024.02.28 |
| flask 웹개발 기초 정리 - 1 (0) | 2024.02.26 |
| Flask 시작하기 - flask-restx (Namespace, Model) (1) | 2024.02.24 |


