서버 사이드 렌더링 적용 기준
넥스트는 기본적으로 서버 사이드 렌더링이 되므로 서버 사이드 렌더링을 사용하지 않게 설정하는 경우가 잦다고 합니다. 그렇다면 서버사이드 렌더링의 적용 기준은 무엇일까요?
검색 페이지에 노출되어야 할 때 적용
즉 SNS 특성상 유저의 프로필에 로그인을 하든 안하든 접근할 수 있게끔 처리해주는 것이 필요하며 없는 계정에 대한 예외처리도 필요합니다. 사실 이 부분은 앞서 설명 드렸던 방식과 디테일만 다르지 거의 유사하므로 따로 설명드릴 부분이 없을 것 같습니다.


강의가 갈수록 앞서 했던 내용의 반복이네요. 따로 정리해둘 건 없지만 반복적으로 코드를 따라치면서 왜 이렇게 하는지 생각하고 공부하게 되는 것 같습니다.
강의에서 진행된 사항으론,
1. 게시글 상세 페이지
2. 각 게시글 간 코멘트 추가
3. 이미지 클릭 시 해당 게시글의 원글과 답글 확인

탐색하기 내 트렌드를 클릭하고 인기/최신 및 사용자/팔로우 목록도 볼 수 있게 useRouter 와 useSearchParams 훅을 사용하여 주소창 변경을 통해 구현했습니다. 이 부분은 직접 프로젝트에서 써봐야 더욱 감이 잡힐거 같습니다.
URLSearchParams 객체
쿼리스트링을 다루면서 필요한 개념을 정리해보려고 해요. 매번 대충 보기만하다가 이제야 정리하게 됐네요.
일단 검색 파라미터를 의미하는 쿼리스트링은 URL에서 도메인 및 경로 다음에 오는 '?' 기호로 시작하는 문자열을 의미합니다. 검색, 필터링, 페이지네이션, 정렬 등 여러 용도로 사용이 가능하여 쿼리스트링을 분석할 줄 아는 게 필요합니다.
Domain?key1=value1&key2=value2&...여러 개의 키와 값으로 이루어진 문자열로, & 를 구분자로 하여 여러 개를 보낼 수 있습니다. 또한 하나의 키에 여러 개의 값을 주는 것도 가능하지만 지양됩니다.
그럼 URLSearchParams 란 무엇일까요?
new URLSearchParams();기존에는 문자열로 다뤘다면 요즘은 해당 객체를 사용하여 다루면서 실수를 줄일 수 있게 되었습니다. 위처럼 new 를 사용하여 초기화하고 메서드를 사용하여 쿼리스트링을 다룰 수 있습니다.
new URLSearchParams([
["mode", "dark"],
["page", 1001],
]);
new URLSearchParams("?mode=dark&page=1001");다만 위처럼 키와 값의 쌍으로 이루어진 2차원 배열로 초기화가 가능합니다. 문자열 형태도 가능하니 편하신 방법을 사용하시길 추천드립니다.
- size
- 쿼리스트링에 매개변수 개수를 반환, 하나의 키에 여러 값이 들어갈 경우 키의 개수로 반환됨
- 즉 유일한 키의 개수가 필요한 경우 Set을 사용하여 구해줘야 함
- keys
- 쿼리스트링의 키 배열을 반환
- toString()
- 쿼리스트링을 문자열로 반환, 다만 '?'는 포함되지 않음
- append(키, 값)
- 배열 형태므로 append 를 사용하여 키와 값을 추가해줄 수 있음
- delete(키)
- 특정 파라미터 삭제
- get(키) / getAll(키) <-> set(키, 값) / setAll([ 키, 값], [ 키, 값 ])
- 키를 기준으로 단일 값을 / 배열형태로 담긴 값을 반환
- has(키)
- 특정 파라미터의 존재여부
- sort()
- 쿼리스트링의 오름차순 정렬
다른 속성과 메서드도 있겠지만 이정도만 알아도 활용하는데 충분한 것 같습니다. 대부분 어디서든 사용될 수 있는 개념이라 어려운 것은 없습니다.
URLSearchParams 는 URL 객체와 함께 활용됩니다. URL 객체는 도메인을 포함한 주소를 모두 담아줄 수 있는데, 그중 search 속성을 통해 쿼리스트링을 문자열로 가져올 수 있으나 searchParams 속성을 사용하면 URLSearchParams 형태로 반환하기 때문에 바로 활용이 가능합니다.
무한 스크롤링
x 홈페이지 등의 sns 를 사용하다보면 스크롤만 내려도 새로운 글이 갱신되는 것을 아실겁니다. 이런 기술을 무한 스크롤링이라고 합니다.
해당 기술을 사용할 더미 데이터 핸들러는 우선 /api/postRecommends 입니다. 쿼리스트링을 붙여 마지막 게시글의 넘버링을 커서로 가져와서 그 이후 글을 가져오게끔 처리해줍니다.
/api/postRecommends?cursor=0 형식으로 쿼리스트링을 주면, 아래와 같이 핸들러 안에서 불러올 수 있습니다.
const url = new URL(request.url);
const cursor = parseInt(url.searchParams.get("cursor") as string) || 0;URL 객체는 위에서 설명했다시피 도메인을 포함한 주소를 모두 담아준 객체입니다. request 매개변수 안 url에 해당 정보가 있으므로 URL로 바로 활용해줍니다. 그리고 searchParams 객체를 받아와서 바로 cursor를 get 해주는 것입니다.
http.get("/api/postRecommends?cursor=0", async ({ request }) => {
await delay(3000);
const url = new URL(request.url);
const cursor = parseInt(url.searchParams.get("cursor") as string) || 0;
return HttpResponse.json([
{
postId: cursor + 1,
User: User[0],
content: `${cursor + 1} Z.com is so marvelous. I'm gonna buy that.`,
Images: [{ imageId: 1, link: faker.image.urlLoremFlickr() }],
createdAt: generateDate(),
},
{
postId: cursor + 2,
User: User[0],
content: `${cursor + 2} Z.com is so marvelous. I'm gonna buy that.`,
Images: [
{ imageId: 1, link: faker.image.urlLoremFlickr() },
{ imageId: 2, link: faker.image.urlLoremFlickr() },
],
createdAt: generateDate(),
},
{
postId: cursor + 3,
User: User[0],
content: `${cursor + 3} Z.com is so marvelous. I'm gonna buy that.`,
Images: [],
createdAt: generateDate(),
},
{
postId: cursor + 4,
User: User[0],
content: `${cursor + 4} Z.com is so marvelous. I'm gonna buy that.`,
Images: [
{ imageId: 1, link: faker.image.urlLoremFlickr() },
{ imageId: 2, link: faker.image.urlLoremFlickr() },
{ imageId: 3, link: faker.image.urlLoremFlickr() },
{ imageId: 4, link: faker.image.urlLoremFlickr() },
],
createdAt: generateDate(),
},
{
postId: cursor + 5,
User: User[0],
content: `${cursor + 5} Z.com is so marvelous. I'm gonna buy that.`,
Images: [
{ imageId: 1, link: faker.image.urlLoremFlickr() },
{ imageId: 2, link: faker.image.urlLoremFlickr() },
{ imageId: 3, link: faker.image.urlLoremFlickr() },
],
createdAt: generateDate(),
},
]);
}),
그리고 넥스트에서 무한 스크롤링을 위한 함수를 수정해봅니다. 홈의 추천 게시글 부분에 무한 스크롤링을 구현해줄 것이므로 홈의 기존 prefetchQuery 였던 식을 무한 스크롤링이 들어가줄 곳을 prefetchInfiniteQuery 로 변경해줍니다. 다만 prefetchInfiniteQuery 는 initialPageParam 가 필수 속성입니다.
await queryClient.prefetchInfiniteQuery({
queryKey: ["posts", "recommends"],
queryFn: getPostRecommands,
initialPageParam: 0,
});서버쪽에서 리액트 쿼리로 무한 스크롤링을 위해선 prefetchInfiniteQuery
그리고 리액트 쿼리에서 클라이언트쪽으로 무한 스크롤링을 마무리 짓기 위해선 useInfiniteQuery 로 변경해줘야 합니다.
const { data } = useInfiniteQuery<
IPost[],
Object,
InfiniteData<IPost[]>,
[_1: string, _2: string],
number
>({
queryKey: ["posts", "recommends"],
queryFn: getPostRecommands,
initialPageParam: 0,
getNextPageParam: (lastPage) => lastPage.at(-1)?.postId,
staleTime: 60 * 1000, // 1분
gcTime: 5 * 60 * 1000,
});useInfiniteQuery 는 추가로 intialPageParam과 getNextPageParam 속성이 필요하며, getNextPageParam 의 경우 콜백함수 형태로 작성해줘야 하며, 매개변수로 마지막 페이지의 배열을 읽어옵니다. 배열의 at(-1) 을 해주면 마지막 요소값을 읽어올 수 있기에 위처럼 표현하게 된 것입니다.
위처럼 data 를 불러오게 되면 2차원 배열 형태가 되어, 기존 data.map() 부분이 아래처럼 바뀌게 됩니다.
return data?.pages.map((page, idx) => (
<Fragment key={idx}>
{page.map((post: IPost) => (
<Post key={post.postId} post={post} />
))}
</Fragment>
));
QueryFn 에 사용해준 getPostRecommends 함수 또한 무한 스크롤링이 가능하게끔 기능을 추가해줍니다.
type Props = { pageParam?: number };
export default async function getPostRecommands({ pageParam }: Props) {
const res = await fetch(
`http://localhost:9090/api/postRecommends?cursor=${pageParam}`,
{
next: {
tags: ["posts", "recommends"],
},
}
)
if (!res.ok) {
throw new Error("Failed to fetch data");
}
return res.json();
}무한스크롤링 전용 리액트 쿼리 훅과 함수는 queryFn의 매개변수에 pageParam을 위처럼 가져올 수 있습니다. 핸들러로 cursor를 지정해준 것처럼 쿼리스트링을 추가해줍니다.
그 다음 페이지를 불러오는 함수를 언제 호출하는지에 대한 함수가 필요합니다.
마우스의 스크롤이 홈페이지의 최하단에 도달했을 때를 확인해줘야 하는데, 우선적으로 많이 떠올리는 방식은 DOM의 scrollHeight 를 확인하는 방식일 것입니다.
scrollHeight
문서의 시작부터 끝까지, 전체 높이를 나타내는 속성입니다.
스크롤한 만큼의 높이를 확인하고 싶다면 window.scrollY 를 사용해줍니다.
const totH = document.documentElement.scrollHeight;clientHeight / innerHeight
상단 탭, 주소 표시줄, 즐겨찾기 바, 하단 스크롤바, 문서의 마진 등을 제외한 순수한 뷰포트 높이를 의미합니다. 해당 값은 window의 innerHeight 로도 동일한 값을 반환할 수 있습니다.
const clientH = document.documentElement.clientHeight;
scrollHeight을 사용하는 방식은 addEventListener 의 scroll 함수를 계속해서 체크해줘야 합니다. 이는 당연히 성능상 문제가 발생할 것이며, 이런 스크롤링을 위해 성능을 개선한 것이 바로 Intersection observer 입니다.
Intersection Observer
브라우저의 뷰포트와 요소 간의 교차점을 관찰하여 요소가 뷰포트에 포함되는지 아닌지 판별하는 기능을 제공한다고 합니다. 비동기적으로 실행되어 요소들의 변경사항들을 관찰이 가능한 것입니다.
이 강의에선 페이지의 최하단에 가상의 태그를 두어, 해당 태그가 보일 때 Intersection Observer 이벤트 함수가 실행되도록 한다고 합니다. 그래서 이벤트 함수에서 다음 데이터를 불러오게끔 만드는 로직이라고 합니다.
react-intersection-observer
npm install react-intersection-observer
기본적인 세팅입니다. 페이지의 최하단에 가상의 div 태그를 두어 해당 태그가 보이면 이벤트가 실행되게 할 것이며, react-intersection-observer 의 useInView 훅을 사용하여, threshold 값을 0으로 두어 이벤트가 바로 실행되도록 설정합니다. threshold 값은 픽셀값을 넣어주는 것으로, ref를 속성의 ref 속성에 넣어서 해당 태그가 몇 픽셀 정도 보이면 실행되는지 정해줄 수 있는 값입니다.
export default function PostRecommends() {
const { data, fetchNextPage, hasNextPage, isFetching } = useInfiniteQuery<
IPost[],
Object,
InfiniteData<IPost[]>,
[_1: string, _2: string],
number
>({
queryKey: ["posts", "recommends"],
queryFn: getPostRecommands,
initialPageParam: 0,
getNextPageParam: (lastPage) => lastPage.at(-1)?.postId,
staleTime: 60 * 1000, // 1분
gcTime: 5 * 60 * 1000,
});
const { ref, inView } = useInView({
threshold: 0,
delay: 0,
});
useEffect(() => {
if (inView) {
!isFetching && hasNextPage && fetchNextPage();
}
}, [inView, isFetching, hasNextPage, fetchNextPage]);
return (
<>
{data?.pages.map((page, idx) => (
<Fragment key={idx}>
{page.map((post: IPost) => (
<Post key={post.postId} post={post} />
))}
</Fragment>
))}
<div ref={ref} style={{ height: 50 }}></div> // 가상의 태그!
</>
);
}마지막으로 useEffect 를 useInView 훅으로 가져온 inView 값을 사용하여 조정해줍니다. inView 는 단어 그대로 ref로 지정해준 태그가 보여지면 true, 보이지 않으면 false 를 의미하는 값입니다.
여기서 위의 예제에 비하여 useInfiniteQuery 의 값이 늘어났음을 알 수 있습니다.
const { data, fetchNextPage, hasNextPage, isFetching } = useInfiniteQuery<
IPost[],
Object,
InfiniteData<IPost[]>,
[_1: string, _2: string],
number
>({
queryKey: ["posts", "recommends"],
queryFn: getPostRecommands,
initialPageParam: 0,
getNextPageParam: (lastPage) => lastPage.at(-1)?.postId,
staleTime: 60 * 1000, // 1분
gcTime: 5 * 60 * 1000,
});fetchNextPage 는 말그대로 함수로, 다음 페이지를 불러오는 함수입니다.
hasNextPage 는 다음 페이지가 있는지 여부를 boolean 으로 리턴해줍니다. isFetching 또한 다음 페이지를 불러오는 중이라면 boolean 으로 리턴합니다.
useEffect(() => {
if (inView) {
!isFetching && hasNextPage && fetchNextPage();
}
}, [inView, isFetching, hasNextPage, fetchNextPage]);위 함수들을 활용하여, useEffect 로 변화를 감지해주고, ref 지정 태그가 inView 하면, 데이터를 불러오지 않을 때 (!isFetching) 다음 페이지가 있으면 (hasNextPage), fetchNextPage() 함수를 실행하게끔 처리해준 것입니다.
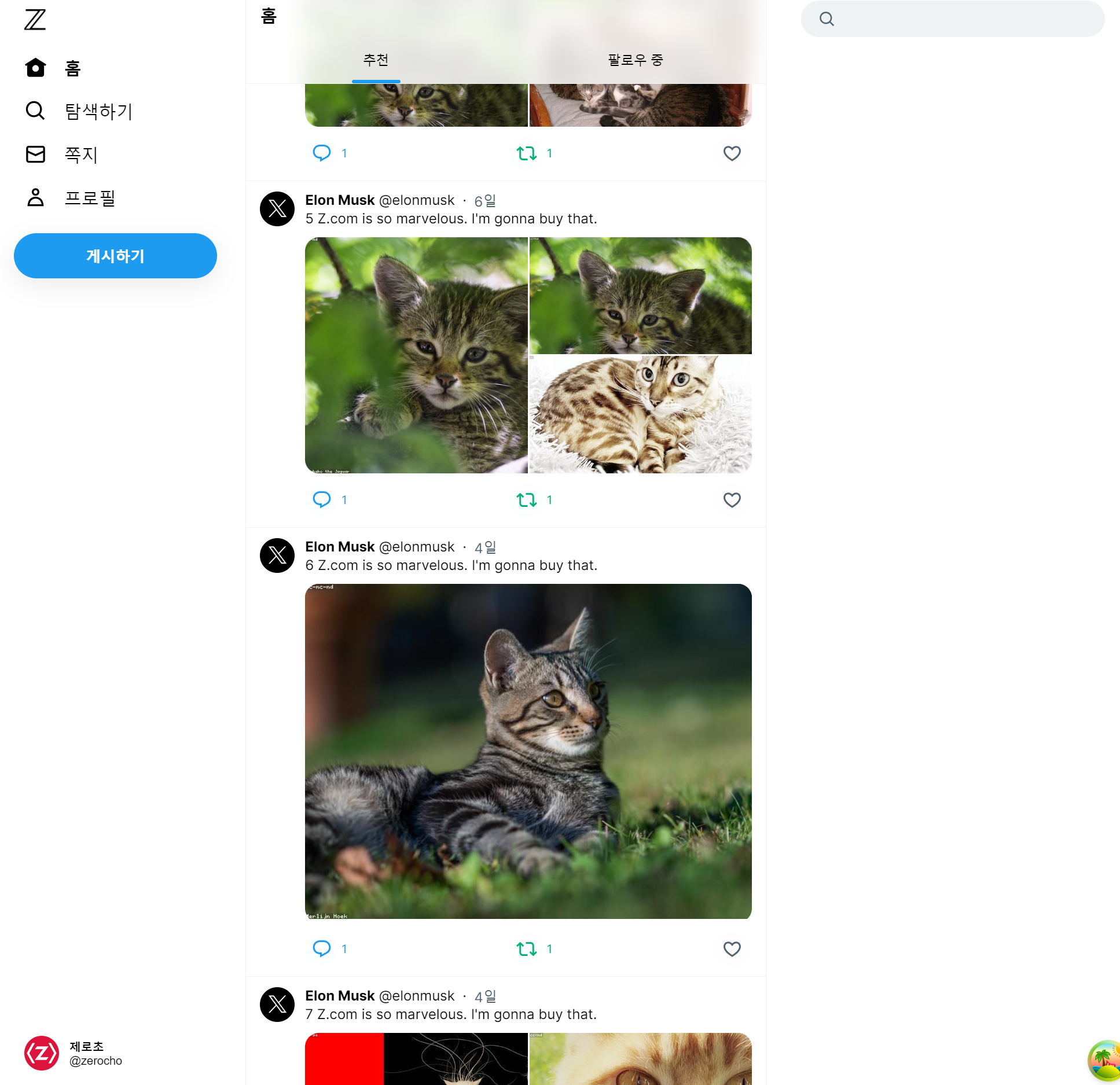
스크롤을 내리면 정상적으로 무한 스크롤링이 가능하게 되었습니다.

넥스트 데브툴내 ["posts", "recommends"] 키의 pageParams의 아이템이 스크롤링함에 따라 늘어남을 확인 가능합니다.
다만 주의할 점은 같은 컴포넌트 내에선 스크롤 정보가 저장되어 컴포넌트별 탭 이동(추천 <-> 팔로우 중)에선 보던 스크롤 복원이 가능하지만 다른 주소창에 갔다가 돌아오면 스크롤 복원이 되지 않습니다.
무한 스크롤링은 react-query 와 react-intersection-observer 가 있으면 간편하게 만들 수 있었습니다.
'Web Study > Next.js' 카테고리의 다른 글
| Next.js로 SNS x.com 클론코딩하기 - 9 (1) | 2024.02.09 |
|---|---|
| Next.js로 SNS x.com 클론코딩하기 - 8.5 (1) | 2024.02.08 |
| Next.js로 SNS x.com 클론코딩하기 - 7 (2) | 2024.02.02 |
| Next.js로 SNS x.com 클론코딩하기 - 6 (2) | 2024.01.30 |
| Next.js로 SNS x.com 클론코딩하기 - 5 (1) | 2024.01.25 |



