요즘 딥러닝이다, 머신러닝이다 말들이 많아서 여러 책을 읽어보고 있다.

인공지능
사람처럼 똑똑한 기계
머신러닝이란
인공지능을 구현하는데 성공한 방법...
어떤 사람이 특정 영화를 좋아할지 여부와 같은 분류
사람의 키와 같은 정량적 예측을 함으로써 데이터를 의사결정으로 변환해주는 도구와 기술의 집합을 의미
딥러닝
머신러닝을 활용한 인공지능의 고도화 방법
머신러닝은 기본적으로 공식을 알려주고 답을 구하게 한 방법이 아닌, 답을 알려주고 공식을 깨우치게 한 것이다.
문제와 답을 보며 공식을 깨우치게 한 과정을 Learning 이라 칭하게 했고 기계가 공부한다는 것을 머신러닝이라고 부르게 된 것이다.
비지도학습
답을 알려주고 공식을 기계가 깨우치게 하는 것이 머신러닝의 기본인데, 답을 알려주지 않고 공부시키는 방식을 의미
강화학습
문제도 답도 안주고 컴퓨터를 어떤 환경에 두고 상점과 벌점의 기준을 세워 컴퓨터가 행동을 할 때마다 제약을 둔다.
그 다음 피드백을 주면서 상점에 해당하는 행동만 하게끔 만드는 방식을 강화학습이라 한다. (ex. 알파고)
Orange data mining
코딩 없이도 인공지능 데이터 분석을 할수 있는 프로그램
Data Mining
Ferenc Borondics, Ph.D. "The scientific community is in need of tools that allow easy construction of workflows and visualizations and are capable of analyzing large amounts of data. Orange is a powerful platform to perform data analysis and visualization,
orangedatamining.com
(보통 인공지능 프로그래밍을 다루기 위해선 Python 을 다룬다.)
https://www.youtube.com/watch?v=HXjnDIgGDuI&list=PLmNPvQr9Tf-ZSDLwOzxpvY-HrE0yv-8Fy
Orange 실행
Options > Add-ons 로 아래 두가지 옵션을 선택한다.

데이터 분석
많은 양의 자료를 요약 및 정리하여 특성을 파악한 뒤 다양한 방면에 적용해보는 행위를 의미한다.
객관식 예측 (classification)
데이터를 특정 범주로 분류하는 것을 의미
새로운 데이터가 어떤 범주에 속할지 예측하는 기법
이직 예측하기
1. 기존 직원들의 정보(나이, 성별, 출신학교, 전공, 부서, 연봉 등 회사에서 수집 가능한 데이터)를 모아 적기
2. 그 결과 현재 직원이 이직했는지 안했는지 표시
3. 직원 정보와 이직 유무라는 결과 사이 어떤 관계가 있겠는지 인공지능에서 공부시킨다
여기서 직원들의 정보는 문제이며 이직 유무는 답인 것이다.
인공지능은 문제와 답을 보고 그 사이에 어떤 규칙이 숨어있는지 수많은 계산을 거쳐 공식을 만들어낸다
Orange 프로그램 실행 ->
New 로 생성 ->
File 탭 클릭 ->
File이 생기면 더블 클릭해줘서 직원 정보가 담긴 파일을 넣어준다.

여기서 아래의 columns 를 보면 name, type, role, values 로 나누어져 있다.
- Name 은 변수명
- Type 은 변수의 유형
- Role 은 변수의 역할
- Values 는 변수의 값
Type - 변수의 유형
숫자는 Numeric 타입이며
Categorical 타입은 몇 가지의 보기로 이루어져있는 범주형 변수 타입을 의미한다.
Role - 변수의 역할
데이터 분석에 있어 문제/재료/원인의 역할을 하는 변수들은 Feature으로 표시하고
Target은 답/목적/결과의 역할을 의미한다.
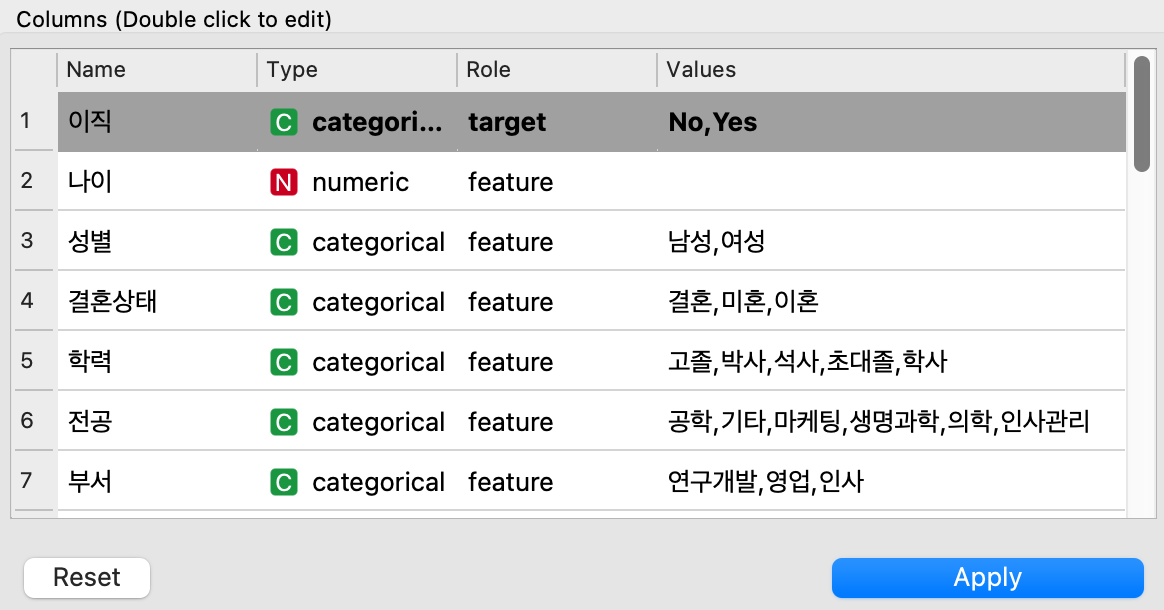
즉, 답에 해당하는 target 이 하나라도 있어야 등록이 가능하다!

model - 인공지능 데이터 분석에서 사용되는 모델
- Neural Network 신경망
- Random Forest 랜덤 포레스트
- SVM 서포트 벡터 머신
- Naive Bayes 나이브 베이즈

File 을 클릭하여 빈곳에 드래그하면 아이콘 선택창이 뜨고, Test and Score 를 만들어준다.
-> 각 모델들에 File -> 모델 -> Test and Score 을 연결시켜준다
-> 잠시 Running 후 Test and Score 를 더블클릭하여 모델의 테스트 결과(성능)를 확인한다

F1 탭 부분을 종합평가로 높은 순서로 보면 신경망이 86.6% 확률로 이직할 직원을 예측한다는 것을 추정할 수 있다.
다음은 Confusion Matrix 를 사용하여 각 모델별 성능을 구체적으로 확인해줄 수 있다.

이 창은 구체적으로 어떤 모델이 어떤 경우는 맞히고 어떤 경우는 틀렸는지 확인할 수 있다.
여기까지가 인공지능에게 기존 직원들의 데이터를 가지고 이직의 상관관계를 공부시켜 예측모델까지 만들어 본 것이라고 한다!
해당 예측모델을 가지고 이직할지 안할지 모르는 직원의 정보를 인공지능에게 보여주고 앞으로 어떻게 될 것인지 물어볼 수 있게 된 것이다.
적용하기
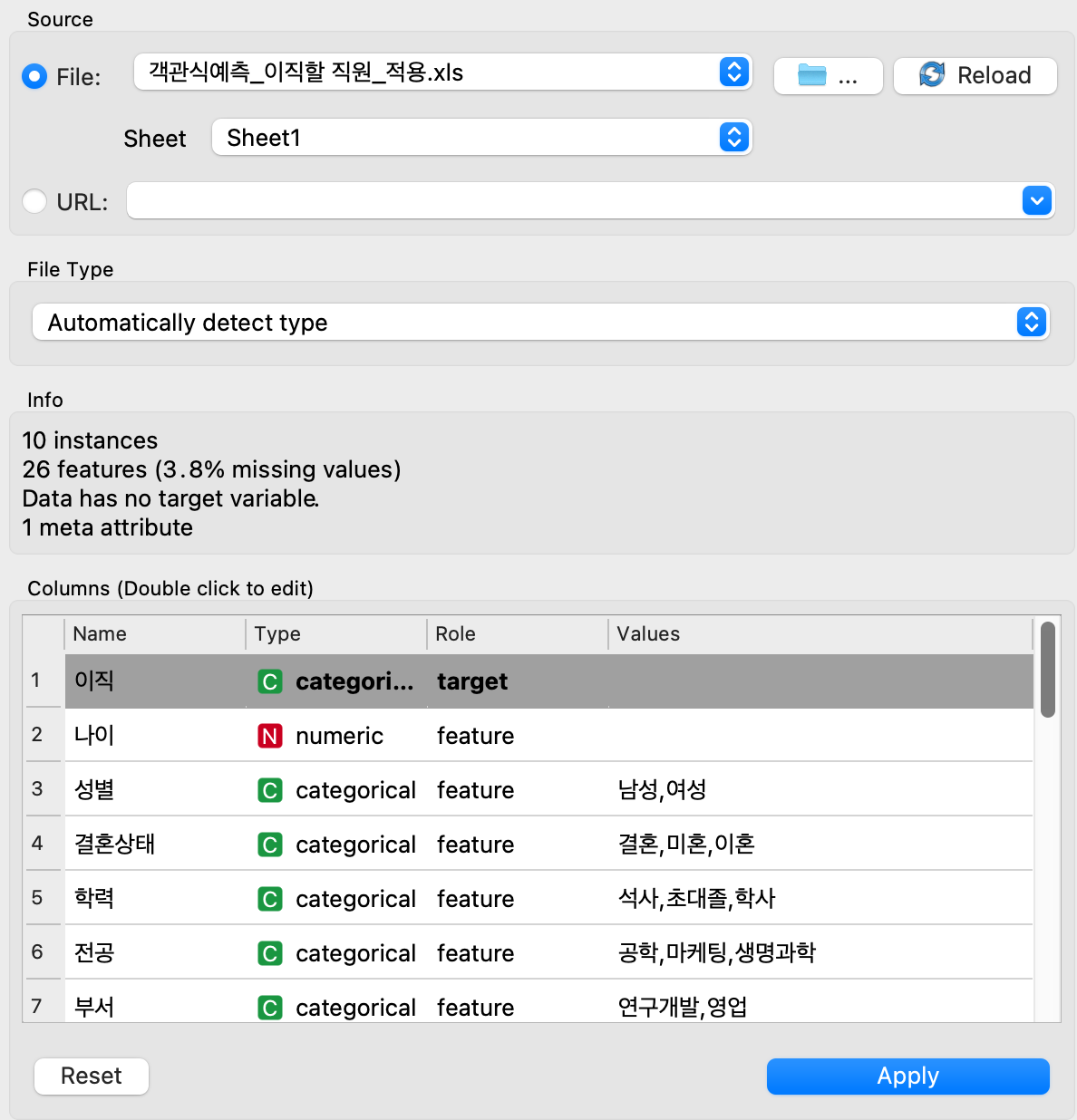
위의 파일을 만들고 Predictions 를 만들어준다.

이처럼 모델들과 이직할 직원들을 예측하는 파일을 Predictions 에 연결해주면 모델에 따라 해당 직원이 이직할지 안할지 결과를 도출해낸 것을 확인해줄 수 있다.
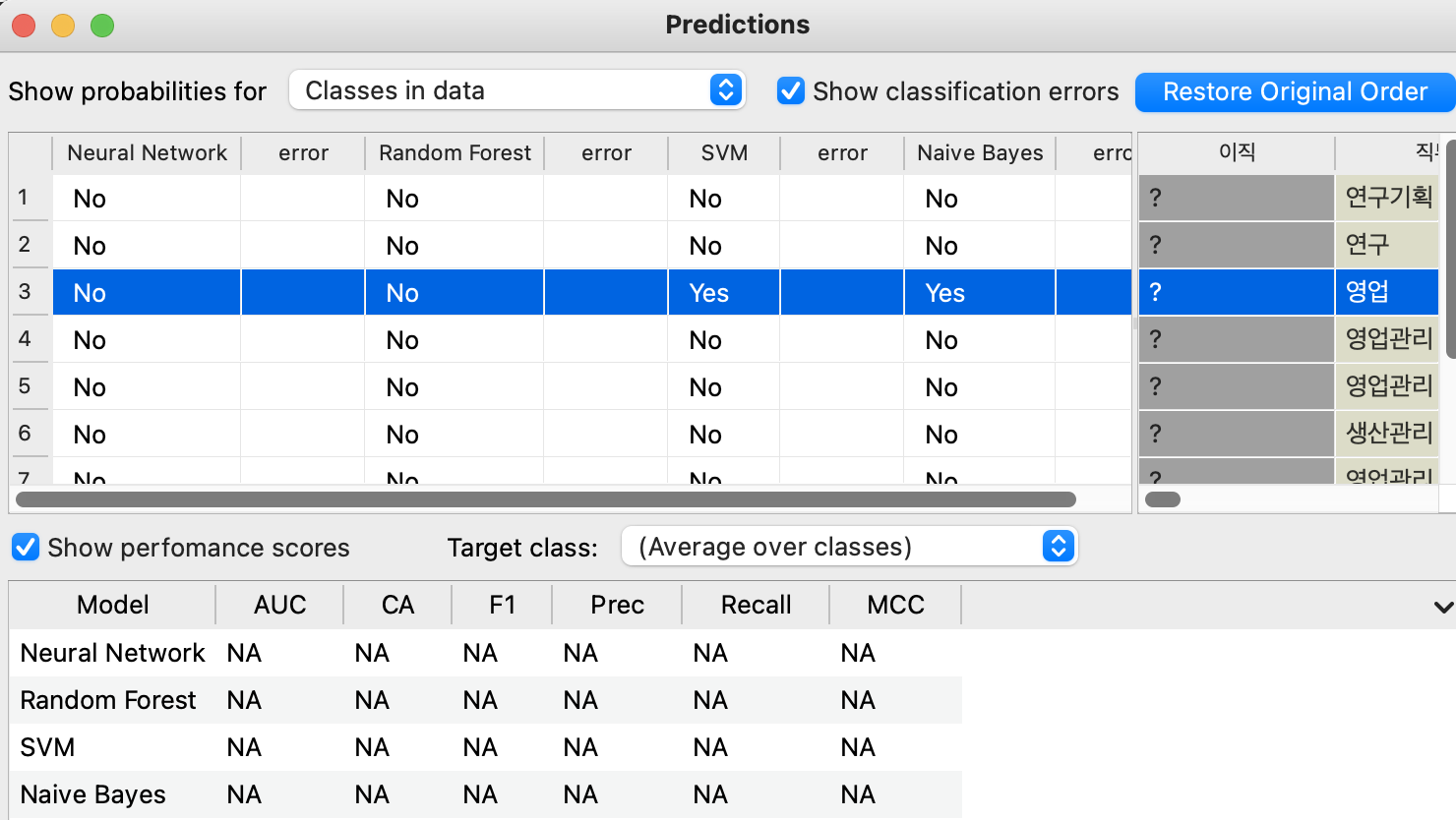
Show probabilities for 의 항목으로 %도 확인이 가능하다.
이렇게 간단하게 인공지능을 사용하여 예측모델을 만들고 실제 사례에 적용해보았다.
여기서 사용된 모델의 대한 설명은 따로 포스팅하는걸로!
'Ect. > 머신러닝 맛보기' 카테고리의 다른 글
| 인공지능 모델 - Neural Network (0) | 2023.06.29 |
|---|
